
코드몽키
[Data Structure] 큐(Queue) 본문
Queue
큐(Queue)는 대기열에 가장 먼저 추가된 요소가 가장 먼저 제거되는 선입선출(FIFO) 원칙을 따르는 자료구조이다.
먼저 삽입된 데이터가 먼저 제거되는 특성을 가진다. 이러한 특징 때문에 큐는 순서 보장, 흐름 제어, 비동기 처리가 필요한 다양한 컴퓨터 시스템에서 핵심적인 역할을 수행한다.
ADT에서 정의한 큐의 기본연산
| 연산 | 설명 | 시간 복잡도 |
| create | 큐 생성 또는 초기화 | O(1) |
| enqueue | 큐의 뒤(rear)에 요소 삽입 | O(1) |
| dequeue | 큐의 앞(front)에서 요소 제거 후 반환 | O(1) |
| peek | 큐의 앞(front) 요소 확인 | O(1) |
| isEmpty | 큐가 비어있는지 확인 | O(1) |
| isFull | 큐가 가득찼는지 확인(배열 기반) | O(1) |
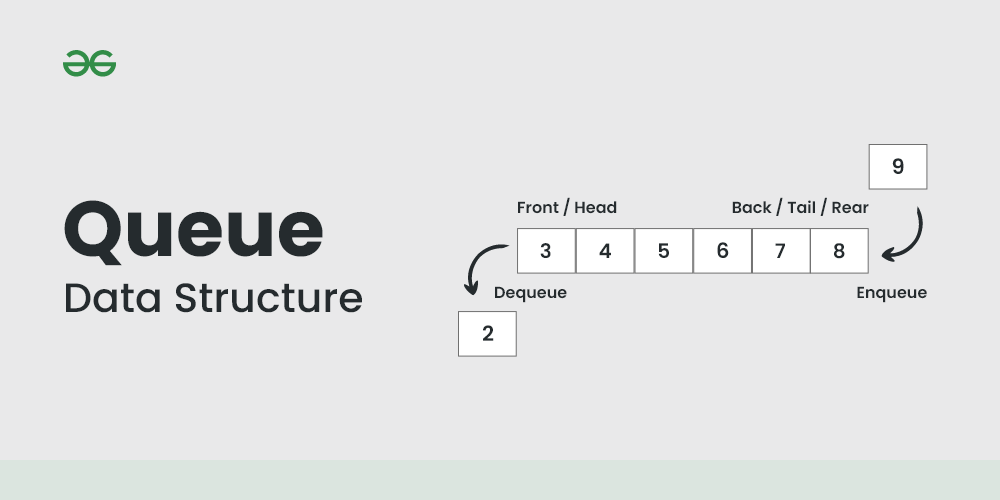
큐는 두 개의 포인터(인덱스)를 기반으로 동작한다.
Front는 큐에서 데이터를 꺼내는 위치이고 Rear는 큐에서 데이터를 삽입하는 위치이다. 삽입(enqueue)은 Rear에서, 삭제(dequeue)는 Front에서 이루어진다. 이로 인해 큐의 모든 기본 연산(enqueue, dequeue, peek)은 평균적으로 O(1)의 시간 복잡도를 가진다.
컴퓨터 시스템에서는 서로 다른 속도로 동작하는 장치 간 데이터 전송 시 속도 차를 완충하기 위하여 큐의 형태로 버퍼가 사용된다.
예를 들어, 키보드 입력 버퍼(사용자가 키를 누르는 속도와 CPU가 입력을 처리하는 속도의 차이를 완화), 네트워크 패킷 버퍼(네트워크 카드(NIC)와 CPU 간 송수신 속도 차이 해결), 디스크 I/O 버퍼(저장 장치와 메모리 간 전송 속도 차이 보정) 등 생산자-소비자(Producer-Consumer) 모델에서 데이터의 순서를 보장하며 안전하게 전달하는 핵심 자료구조 이다.
또한 운영체제에서는 큐를 기반으로 CPU 스케줄링과 입출력 스케줄링의 실행 순서를 제어 하며, 알고리즘에서는 그래프, 트리 등 비선형 자료구조의 탐색과 순회에도 필수적으로 사용된다.
큐의 구현 방식에는 배열 기반 구현, 연결리스트 기반 구현, 그리고 삽입 순서가 아니라 우선순위에 따라 요소가 제거되는 우선순위 큐(Priority Queue) 방식이 있다. Java Collection Framework에서 큐(Queue)는 Queue 인터페이스만 제공한다. 따라서 개발자가 직접 구현할 수도 있으며, 표준 구현체(LinkedList, PriorityQueue, ArrayDeque)를 사용할 수도 있다.
아래 예시는 배열 기반 원형 큐를 직접 구현한 코드이다.
public class ArrayQueue {
private int[] queue; // 큐 배열
private int front; // 첫 요소 인덱스
private int rear; // 마지막 요소 인덱스
private int size; // 현재 요소 개수
private int capacity; // 큐 용량
// 생성자
public ArrayQueue(int capacity) {
this.capacity = capacity;
this.queue = new int[capacity];
this.front = 0;
this.rear = -1;
this.size = 0;
}
// 큐가 비었는지 확인
public boolean isEmpty() {
return size == 0;
}
// 큐가 가득 찼는지 확인
public boolean isFull() {
return size == capacity;
}
// 요소 삽입
public void enqueue(int item) {
if (isFull()) {
throw new IllegalStateException("Queue is full");
}
rear = (rear + 1) % capacity; // 원형 구조
queue[rear] = item;
size++;
}
// 요소 제거 및 반환
public int dequeue() {
if (isEmpty()) {
throw new IllegalStateException("Queue is empty");
}
int item = queue[front];
front = (front + 1) % capacity; // 원형 구조
size--;
return item;
}
// 첫 요소 반환 (삭제 X)
public int peek() {
if (isEmpty()) {
throw new IllegalStateException("Queue is empty");
}
return queue[front];
}
// 현재 큐 상태 출력
public void printQueue() {
System.out.print("Queue: ");
for (int i = 0; i < size; i++) {
System.out.print(queue[(front + i) % capacity] + " ");
}
System.out.println();
}
// 테스트
public static void main(String[] args) {
ArrayQueue q = new ArrayQueue(5);
q.enqueue(10);
q.enqueue(20);
q.enqueue(30);
q.enqueue(40);
q.printQueue(); // 10 20 30 40
System.out.println("Dequeue: " + q.dequeue()); // 10
q.printQueue(); // 20 30 40
q.enqueue(50);
q.enqueue(60);
q.printQueue(); // 20 30 40 50 60
System.out.println("Front: " + q.peek()); // 20
}
}
큐의 동작 원리를 이해하면 단순히 자료구조 하나를 아는 것을 넘어, 운영체제에서 프로세스가 차례대로 CPU를 할당받는 방식, 네트워크 패킷이 대기열에서 처리되는 흐름, 그리고 다양한 알고리즘에서 데이터가 어떻게 순서대로 관리되는지까지 데이터 처리의 근본 메커니즘을 직관적으로 이해할 수 있다.
Reference
https://www.geeksforgeeks.org/dsa/queue-data-structure/
'Data Structure' 카테고리의 다른 글
| [Data Structure] 해시(Hash) (0) | 2025.08.18 |
|---|---|
| [Data Structure] 스택(Stack) (0) | 2025.08.09 |
| [Data Structure] ADT(Abstract Data Type) 추상적 자료구조 (3) | 2025.08.08 |