
코드몽키
[Data Structure] 해시(Hash) 본문
Hash
해시(Hash)는 키(Key)를 일정한 규칙(함수)를 통해 고정된 크기의 값으로 변환하는 과정을 말한다.
해시(Hash Function)는 바로 그 변환 규칙을 일컫는다. 임의의 크기의 입력(문자열, 숫자)을 받아 고정된 크기의 해시 값(Hash Value, Hash Code)을 반환한다. 해시 자료구조는 이 해시 함수를 활용해서 데이터를 효율적으로 저장하고 검색하는 자료구조를 말한다. 저장된 자료의 양과 관계없이 평균적으로 상수 시간(O(1))에 삽입과 조회가 가능한 자료구조가 바로 해시 테이블이다.

해시 기반 자료구조를 Java에서 실제로 사용한다고 가정해보자 먼저 car 라는 키 값(Key)을 가지고 자동차의 가격(Value) 2000 을 저장하려고 한다. 그럼 코드에선 Hash Function이 동작하여 키 값을 Hash 값으로 변경해 준다. 정수 값으로 나온 Hash값은 내부 배열의 사이즈로 나뉘어 그 나머지값이 배열의 인덱스가 된다. 이렇게 해서 배열의 bucket에 키 밸류 값을 쌍으로 하는 Node가 해시 기반 자료구조에 저장되게 된다.
Hash Collision
Hash Collision은 서로 다른 Key가 같은 해시 값(Hash Code) 또는 같은 배열 인덱스로 매핑될 때 발생한다. 즉, 해시 함수가 Key를 정수로 변환했지만, 내부 배열 크기는 제한되어 있기 때문에 서로 다른 Key가 같은 자리로 겹치는 상황을 말한다.
예를 들어, 배열의 크기가 5라고 가정을 해보자
| Key | Hash Code | Index (Hash % 5) |
| apple | 12 | 2 |
| pear | 17 | 2 |
위와 같은 상황이라면 "car"와 "cat"이 같은 인덱스 2에 매핑 됨으로 충돌이 발생하게 된다.
이러한 해시충돌을 해결하는 방법으로 Chaining 기법과, Linear Probing 기법이 있다.
먼저 Chaining 기법은 Open Hashing의 한 방법으로, 해시 충돌이 발생하면 해당 버킷이 가리키는 연결 리스트에 새 Node를 추가하여 데이터를 저장하는 방식이다. 즉 충돌이 발생하면 같은 버킷 안에서 연결 리스트로 데이터를 연결한다고 이해하면 된다.

Chaining 기법에 따라, 사과 가격 3000원 뒤에 연결 리스트로 3200원의 배 가격이 추가 된다.
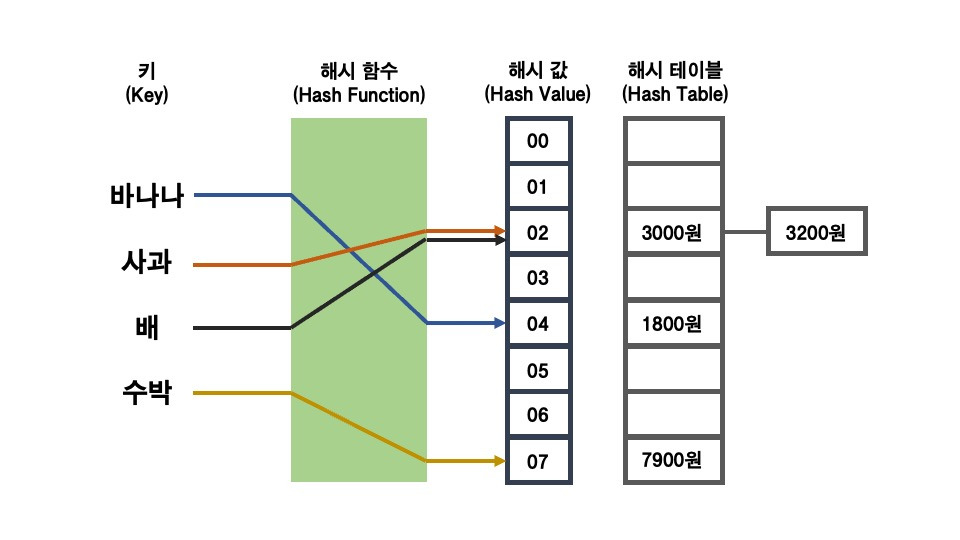
다음과 같이, 배의 가격인 3200원을 사과 가격 뒤에 추가로 연결시켜서 저장함을 볼 수 있다.
체이닝의 경우 버켓이 꽉 차더라도 연결리스트로 계속 늘려가기에, 데이터 주소값의 변화는 없다(Closed Addressing). 하지만 개방 주소법(Open Addressing) 방식은 해시 충돌이 발생하면 다른 버켓에 데이터를 삽입 한다. 개방 주소법(Open Addressing)에는 대표적으로 3가지가 있다.
선형 탐색(Linear Probing): 해시 충돌 시 다음 버켓, 혹은 몇 개를 건너뛰어 데이터를 삽입
제곱 탐색(Quadratic Probing): 해시 충돌 시 제곱만큼 건너뛴 버켓에 데이터를 삽입
이중 해시(Double Hashing): 해시 충돌 시 다른 해시함수를 한 번 더 적용한 결과를 사용

사과와 배의 충돌 문제를 Linear Probing으로 해결하면 중복되는 해시 값인 02 다음 값 03부터 순회를 시작하여 빈 해시 테이블 공간을 찾는다. 03 인덱스가 비어있으니, 03에 배의 가격 데이터를 입력하면 된다. 비어 있던 공간인 03 부분의 해시 테이블 값이 3200원이 저장이 된다.
클러스터링
선형탐색(Linear Probing)의 문제점으로는 순차적으로 탐색하다보니 특정 구간에만 데이터가 뭉쳐 그룹이 형성되는 현상이 발생하는데 이러한 현상을 클러스터링이라고 한다. 클러스터링 현상은 탐사 시간이 오래걸리게 하고, 전체적으로 해싱 효율을 떨어뜨리는 원인이 된다.
또한, 오픈 어드레싱 방식은 버킷 크기(전체 슬롯의 개수) 보다 큰 경우에는 삽입이 불가능 하기에 기준이되는 로드 팩터 비율을 넘게되면, 그로스팩터(Growth Factor)의 비율에 따라 더 큰 크기의 또 다른 버킷을 생성한 후 새롭게 복사하는 리해싱(Rehashing) 작업이 일어나게 된다.
로드 팩터(Load Factor)와 그로스 팩터(Growth Factor)
로드 팩터는(Load Factor)는 해시 테이블이나 동적 배열 같은 자료구조에서 용량이 현재 얼마정도 채워졌는지 나타내는 비율이고, 그로스 팩터(Growth Factor)는 위와 같은 자료구조에서 용량을 늘리는 비율을 나타내는 개념입니다. “새로 할당할 공간이 기존 공간의 몇 배가 될지”를 결정하는 값이라고 이해 할 수 있다.
Java로 예를 들면 대표적인 HashMap이 자바의 해시 테이블 구현채 HashMap의 Growth Fact는 2이며, 이 의미는 HashMap에 저장되는 데이터가 로드팩터(0.75)를 넘어서면 2배 큰 메모리 영역을 새롭게 할당하는 리사이징이 발생하며 기존 데이터를 새로운 배열로 옮긴다 이때 해시 버킷 인덱스를 다시 계산(리해싱)한다. 기존의 해시 충돌 체인은 새로운 버킷에 맞춰서 분배한다.

위 그래프와 같이 보통은 오픈 어드레스 방식이 체이닝 방식보다 성능이 좋지만, 80% 이상 차게되면 급격하게 성능이 저하되는 것을 확인할 수 있다. 자바 같은 경우 해시 테이블 구현체인 HashMap은 연결 체이닝 방식으로 구현되어 있으며, 파이썬, 루비 같은 스크립트 언어들은 오픈 어드레스 방식으로 성능을 높이는 대신, 파이썬의 경우 로드팩터를 0.66, 루비의 경우 0.5로 로드팩터를 작게 잡아 성능 저하 문제에 대응한다.
Reference
https://www.geeksforgeeks.org/dsa/what-is-hashing/
'Data Structure' 카테고리의 다른 글
| [Data Structure] 큐(Queue) (4) | 2025.08.13 |
|---|---|
| [Data Structure] 스택(Stack) (0) | 2025.08.09 |
| [Data Structure] ADT(Abstract Data Type) 추상적 자료구조 (3) | 2025.08.08 |